Treechop

Reproducing the tree gridworld for investigating goal misgeneralization
View the code for TreeChop here. View the code for goal misgeneralization in procgen here.
This work was done for my mini-project as part of BlueDot Impact’s technical AI alignment course, between May and June 2024.
Aims
I aimed to create a realization of the description of a tree gridworld given in Shah et al (2022), ready to be used in a project to replicate their goal misgeneralization results by also being able to run a reinforcement learning agent through it. Through this project, I aimed to build up reinforcement-learning environment software engineering experience and eventually to get a ‘gearsy’ inside-view/ understanding of this specific instance of inner alignment and goal misgeneralization.
Background
The paper ‘Goal Misgeneralization: Why Correct Specifications Aren’t Enough For Correct Goals’ (Shah et al, 2022) investigates goal misgeneralization in deep reinforcement learning agents, resulting from distributional shift, across multiple settings.
One very simple environment described by Shah et al (2022) in their paper is that of the tree gridworld. As for the other settings in the paper, they use the environment to demonstrate how an optimal-seeming policy has actually been learned from a capable agent misgeneralizing to a proxy goal. This setting is a 10*10 grid in which trees spawn at a given rate, proportional to how many trees are left in the environment, whilst the agent can only move toward and chop trees. However, unlike the other settings studied, this environment is an online, reset-free, ‘infinite’ setting. That is:
… the agent acts and learns in the environment, without any train / test distinction and without an ability to reset the environment (preventing episodic learning). To cast this within our framework, we say that at a given timestep, [the training distribution] consists of all past experience the agent has accumulated. The optimal policy in this setting is to chop trees sustainably: the agent should chop fewer trees when they are scarce, to keep the respawn rate high. (Shah et al, 2020)
In this setting, the distributional shift that gives rise to the exhibition of goal misgeneralization is caused by the agent’s own interaction with the environment. The agent is rewarded +1 per tree chopped down. The authors find that the agent initially fails to learn the intended goal of ‘chop trees sustainably’, instead learning to chop trees quickly until there are very few trees and an extended period of very low reward whilst the agent learns that chopping with fewer trees in the environment is non-optimal.
There is no accompanying open-sourced code or released images for the tree gridworld (confirmed with the authors), but it should be possible to replicate the environment from the description in the paper:
10 × 10 gridworld with entities (initially): agent, 10 trees. The agent is provided the full gridworld as a 12 × 12 × 2 one-hot encoded image in its observations. Chopping a tree provides +1 reward. If there are fewer than 10 trees, the probability of a new tree spawning at a random empty location is given by:
r = max(rmin, rmax × log(1 + ncurrent)/ log(1 + nmax))
where rmin and rmax are the minimum and maximum respawn rates, and ncurrent and nmax are the current and maximum number of trees. In the experiment shown in Figure 3 we set rmin = 10−6 , rmax = 0.3, and nmax = 10.
I decided that I would make the gridworld in the style of other OpenAI procgen games, rather than use the binary on-off grid of squares described in the paper. This of course makes the environment more visually complex, but would also allow me to easily plug code into another, open-sourced, paper code base that helped me understand how to train an agent in this environment.
The paper ‘Goal Misgeneralization in Deep Reinforcement Learning’ (Langosco et al, 2021) released open-source codebases forked from both OpenAI’s Procgen benchmark repo and a PyTorch implementation of a PPO agent for OpenAI’s procgen. These three resources formed the basis for my being able to create the extended tree gridworld and be ready to plug in a Proximal Policy Optimization agent1.

What I have achieved
I have taken the conceptual description of an environment in a paper and embellished it to produce a full, open-sourced procgen implementation of this environment based on OpenAI’s procgen. Specifically, I have taken the description of a one-hot-encoded binary tree gridworld in Shah et al. (2022) and created an open-source version of this environment which is uses C++ and bespoke artefacts to create a more complex visual environment, whilst preserving the principles of the originally described gridworld, such as the 10*10 grid layout and the spawning of trees.
I have subsequently tested out and got working a PPO reinforcement learning agent training process for this gridworld, and trained this agent with simple-to-run-in-CPU-environment parameters. I have set up and improved upon the codebase released by Langosco et al (2021) to do this, and I am now essentially ready to transfer the set-up to a HPC environment to make use of GPUs with which to carry out training and attempt to replicate the goal misgeneralization results found on the tree gridworld in Shah et al (2022).
A training run for a PPO agent learning a policy in Treechop is shown below. Though this isn’t robust, it’s an example of an agent working with an easily adaptable set up in an environment I have built.

What I did
- I researched the tree gridworld thoroughly to understand what resources were available - this involved reaching out to the authors, reading the original and closely related papers, and investigating codebases. This led to the discovery that code for goal misgeneralization studied elsewhere by Langosco et al (2021) was open source, and subsequently to the procgen and PPO agent repos.
- I forked and built the modified procgen environment from source. Following the installation steps was not simple - I had to contend with conda and cmake, for which I subsequently reported as the answer to an issue here, and deal with a lack of documentation between the original OpenAI procgen repo and the re-implementation of it in the repo I actually built from.
- I tested the installed procgen environments without agents, e.g. running
python -m procgen.interactive --env-name coinrun_aisc --level-seed 6 - I then set about making my own procgen game. I used bigfish.cpp as an initial template to start messing around in C++, having never used this language before. I designated the name of the tree gridworld to be ‘Treechop’. After messing around a bit, I realized that the miner.cpp game mechanics were much closer to what I wanted in the end product so I started again.
- I made my own pixel art for the environment and figured out how to load these in.
- With a lot of trial and error, I achieved a basic grid world game! I also gave it the additional optional features of a easy (10x10) or hard (20x20) mode, and when a tree is cleared by the treechopper for the tree to either disappear or for a stump to randomly remain in place for a few steps before that disappears too. The game is runnable in the terminal with the command
python -m procgen.interactive --env-name treechop --distribution-mode easy

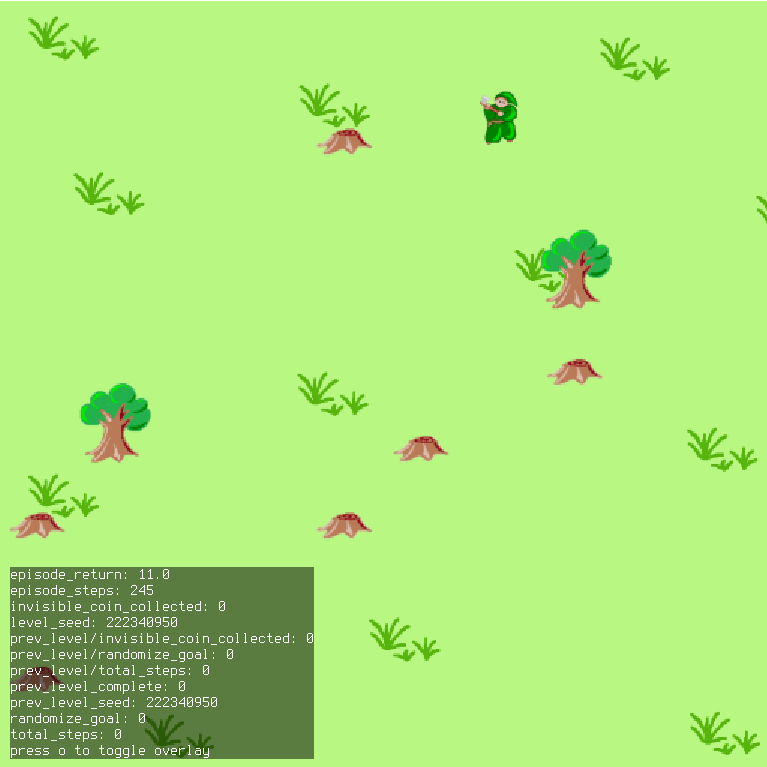
- I then set about forking to my own repo and running the main codebase used by Langosco et al (2021) to replicate their basic setup for goal misgeneralization with procgen environments (e.g. Coinrun), so that once this was running I could just swap in my new treechop game. Again, there were a host of laborious dependency issues, but I was eventually able to create an almost-clean
.ymlfor future installs. - I first got a random agent running in Treechop with logging output, though not visual output, using example scripts provided from the procgen benchmark repo and the gym3 repo.
- I then plugged my Treechop game into the training procedure and associated commands, and through minimal trial and error got this running with
python train.py --exp_name treechopper --env_name treechop --distribution_mode easy --param_name debug --num_timesteps 50000 --num_checkpoints 2 --seed 1080 --gpu_device 0 --device cpu - I figured out how to add the video-record wrapper whilst training the agent. This was not simple because the method seems to have had well-documented bugs anyway, but the specific error I was encountering wasn’t recorded anywhere and could only have been definitively solved by updating the imageio-ffmpeg package, something which procgen didn’t allow for. In the end, I had to solve it with a temporary patch in my local installation2.
- Combining the video recording wrapper with a simple-hyperparameter training run, I was able to record an instance of a PPO agent learning. In the above sample, where the agent is approaching 100,000 timesteps of continuous gameplay (approx. 1 hour).
Things I have learned
I have learned to create a simple, small game using C++, and how to use procgen, gym and PyTorch to get a PPO agent working in this environment. Having never touched C++ previously, and not having implemented my own RL agent before, these are steps that make going further to replicate the study seem much more manageable.
It’s really good to keep on track, but it’s also really good to know when to pivot. I started this project with the aim of replicating the full tree gridworld experiment and then opening up the agent to look inside. This was too big a goal and it really helped to monitor my progress and de-scope after examining how much work it would take for me to feel comfortable setting up in a HPC environment. To de-scope, I researched the possible paths carefully - for example, I looked into the major cloud providers, thought about how I’d get something remote plugged into my local IDE of choice, picked resources that most closely aligned with those used in the original paper - so I have all the next steps for this lined up, I just removed them from the initial MVP.
I knew this (albeit less intimately) already, but often, untangling other people’s conda dependencies is a bit of a nightmare, especially if they haven’t produced an automated .yml from their environment to comprehensively cover dependencies and versioning information.
Next steps
My next aim is to replicate the goal misgeneralization behavior observed in the original paper. The stretch aim is to investigate the agent’s learned behavior using approaches in mechanistic interpretability to understand _why _the goal misgeneralization is happening, plus make interesting modifications to the set up (e.g., use tree stumps as visual reminders of trees, have a seedling appear first like a ‘warning’ behavior to see if that influences the agent.)
The next steps would be to tidy the repo and refactor the code that I am using to make use of modern dependencies. This would solve dependency issues. This is a less glamorous but probably necessary step.
I also need to figure out a way to count the number of trees at any given point and calculate the policy ‘affinity’ as described in the original paper. I’ll also need to figure out a way to get screenshots rather than a full video of the agent whilst it’s training, deactivating the recorder for the hundreds of hours required. I think it will also be easiest to package up my modified version of the procgen repo so this can be installed as a dependency for others.
Then, I aim to run my code on an NVIDIA V100 for 30 training hours. AWS’s P3 series gives access to these, and for 30 hours this would cost about £45. To enable this step I’ll need to be comfortable setting cost limits in the AWS platform so that I don’t accidentally spend loads of money. The plan would be to set up a free-tier EC2 instance first, to make sure I understand all the ssh and environment set-up steps using conda, and then to replicate that on the GPU instance, following this tutorial.

Reference papers and posts
Goal Misgeneralization: Why Correct Specifications Aren’t Enough For Correct Goals - https://arxiv.org/abs/2210.01790 and https://sites.google.com/view/goal-misgeneralization
Goal Misgeneralization in Deep Reinforcement Learning - https://arxiv.org/abs/2210.01790
Examples of goal misgeneralisation in the wild - https://docs.google.com/spreadsheets/d/e/2PACX-1vTo3RkXUAigb25nP7gjpcHriR6XdzA_L5loOcVFj_u7cRAZghWrYKH2L2nU4TA_Vr9KzBX5Bjpz9G_l/pubhtml
CoinRun: Solving Goal Misgeneralisation - https://arxiv.org/pdf/2309.16166.pdf
https://www.lesswrong.com/posts/Cfe2LMmQC4hHTDZ8r/more-examples-of-goal-misgeneralization
Unsolved Problems in ML Safety - https://arxiv.org/abs/2109.13916
V-MPO: ON-POLICY MAXIMUM A POSTERIORI POLICY OPTIMIZATION FOR DISCRETE AND CONTINUOUS CONTROL - https://arxiv.org/abs/1909.12238
AI Safety Gridworlds - https://arxiv.org/abs/1711.09883
Quantifying generalization in reinforcement learning -https://openai.com/research/quantifying-generalization-in-reinforcement-learning
https://deepmind.google/discover/blog/specifying-ai-safety-problems-in-simple-environments/
https://openai.com/research/procgen-benchmark
Reference repositories and notebooks
https://github.com/google-deepmind/ai-safety-gridworlds/tree/master?tab=readme-ov-file
https://github.com/google-deepmind/pycolab/tree/master
https://github.com/openai/coinrun?tab=readme-ov-file
https://colab.research.google.com/drive/11yqoQgckV3lpe7adN0gkaqUcsKEutiCS?usp=sharing
https://github.com/qqiang00/Reinforce
https://github.com/JacobPfau/procgenAISC/tree/master/procgen
https://github.com/joonleesky/train-procgen-pytorch/tree/master
https://github.com/openai/procgen?tab=readme-ov-file
https://github.com/google-deepmind/lab/tree/master/docs
https://huggingface.co/learn/deep-rl-course/en/unit6/hands-on
https://github.com/google-deepmind/lab
Footnotes
View the code for TreeChop here. View the code for goal misgeneralisation in procgen here.
-
Shah et al (2022) actually use a V-MPO-based agent, rather than PPO. ↩
-
I had to apply a patch to _io.py in ffmpeg because of a consistent keyword error for the argument ‘audio_path’, which wasn’t being set by me, but was throwing an exception. I just added ‘**kwargs’ to the definition of write_frames to solve this. I suspect this is due to package dependency issues, but not clear if it’s affecting anyone else; I can’t find references to this in the Issues on the OpenAI procgen repo. ↩