Building an Impact Assessment Assistant part 3: The evaluation
My team recently launched an internal chatbot for colleagues to locate information from impact assessments and impact assessment guidance in a natural-language interface. As a technical lead on the development of this project, this is the third of three blog posts taking a deeper dive on the technical path that led us to deployment.
Our initial alpha deployment made use of the Azure tools we had available, specifically Azure Web Apps – to allow users in the department to interact with the chatbot for long enough to gather useful feedback. More recently, as the wider team moved over to employing AWS as standard, we also migrated the chatbot to an AWS architecture, but retained the Azure OpenAI model and AI Search endpoints. This is a hybrid approach that we may iterate further in the future, but given the evaluation of the chatbot so far, it made the most sense to retain what we had already shown with both automated evaluation and with users to be a useful product.
To evaluate the RAG chain automatically, the expert economist team we were working with put together 60 questions and gold-standard answers, along with sources – this was an excellent resource for quickly understanding the impact of design decisions like prompt revisions and new chain implementations. We implemented the latest version of RAGAS to evaluate, bringing in a suite of metrics that give us a clearer picture of how well the system retrieves and generates responses.
| Example question | What information should be included in a high-quality SaMBA? |
|---|---|
| Ground truth answer | A high-quality SaMBA should include sector-specific details, the number of businesses in scope, market share, impact on businesses, and appropriate exemption or mitigation measures. Quantitative analysis should be provided where significant differential impacts are anticipated. |
| Chatbot answer | A high-quality Small and Micro Business Assessment (SaMBA) should include the following information, as stated in the Better Regulation Framework guidance: |
- An understanding of the impact of the proposal on small and micro-businesses (SMBs) and whether it will affect them differently than medium and large businesses.
- A description of the policy objective and how much of it is sacrificed by applying a full exemption.
- An estimate of the overall cost to business expected to fall on SMBs, with and without an exemption.
- A quantitative estimate of the proportion of the policy objective sacrificed by applying a full exemption and the overall cost to business expected to fall on SMBs, if feasible.
- Assumptions made during the assessment that will be tested during consultation.
- Information on how data was obtained and analyzed, including any limitations or gaps in the data.
- Consideration of ways to mitigate negative impacts on SMBs.
| It’s important to note that the analysis for a SaMBA should be proportionate to the scale of the impact of the proposal. For high-impact proposals, more detailed analysis and evidence are expected. |
One example question, gold-standard answer and chatbot response from our evaluation set. The chatbot displays typically verbose answers, as do most LLMS by default.
The setup included precision and recall metrics that use an LLM to compare retrieved chunks against a reference, “ground-truth” answer. Semantic Similarity and Factual Correctness helped us assess how close the chatbot’s answers are to the reference, with the former relying on embeddings (so it’s cheap to run) and the latter using an LLM. Faithfulness was a debated addition, but it’s now included to help us understand whether the chatbot is actually using the provided context or just freelancing with general knowledge—especially useful for spotting hallucinations. Cost-wise, a full run across 62 questions is very affordable—around £2 using GPT-3.5-Turbo. We updated this process when we moved to new underlying base models (GPT 4o mini) and used it as a rough mark of performance alongside user testing.
| Metric | Non-technical Description | Technical Description |
|---|---|---|
| LLMContextPrecisionWithReference | Checks how many retrieved chunks of text are useful, based on a trusted source. | Measures proportion of relevant chunks in retrieved_contexts by comparing to ground truth reference using an LLM. |
| LLMContextRecall | Tells you how many important documents were found. | Calculates recall of relevant documents by comparing retrieved contexts to a reference using an LLM. |
| Semantic Similarity | Checks how close the chatbot’s answer is to the correct answer, based on meaning. | Compares ground truth and generated answer using embeddings, using a similarity score, without using an LLM. |
| Factual Correctness | Measures whether the chatbot’s answer is factually accurate. | Uses an LLM to divide answers into claims and compare generated answer to ground truth and assess claim alignment. |
| Faithfulness | Evaluates whether the chatbot’s answer is based on provided sources rather than general knowledge. | Uses an LLM to simplify the answer into claims and checks if those claims are supported by the context. |
A description of each of the metrics used in the automated assessment process.
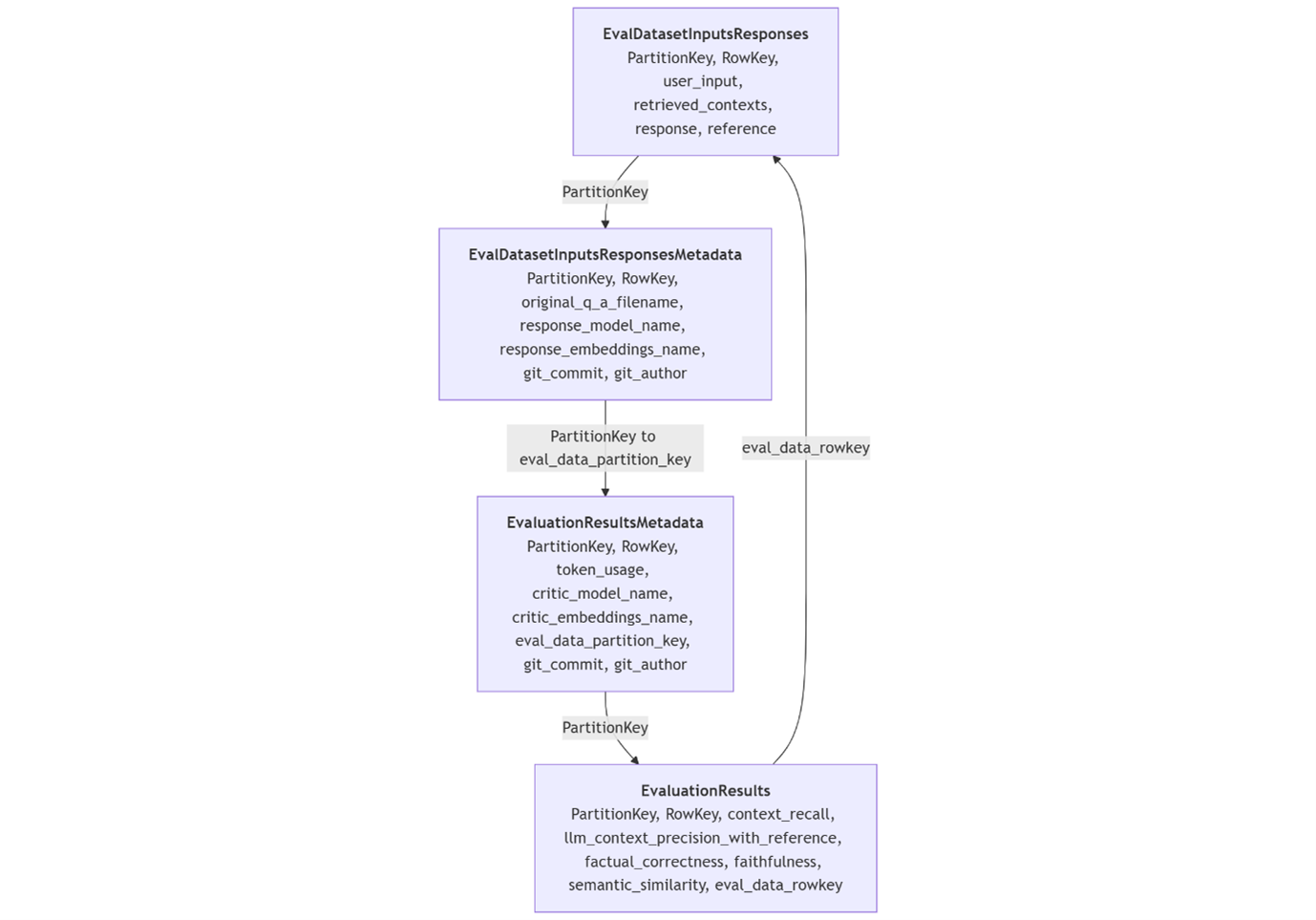
A diagram of the painstakingly-crafted relational table storage for automated evaluation results, which originally existed in Azure Blob Table storage and now sits in files on AWS S3.
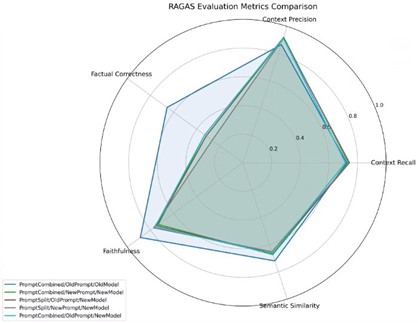
An example of RAGAS results for the bot at one stage in development – we often noticed false negatives that were seemingly to do with comparative length differences between ground truth and chatbot answers.
Automated and LLM-as-a-judge testing will never capture the whole picture for how useful an AI product is for the people it’s being designed for. Therefore, user testing formed a crucial part of our development process. In the first round, we observed participants using the app during a Teams call, which we recorded for later review. This approach allowed us to closely analyse user interactions and identify areas for improvement. Following iteration, we launched an alpha testing trial that ran for a month, allowing a broader group of users to engage with the chatbot and provide in-depth feedback. This phase included a red teaming exercise conducted by the data science team to rigorously test the system’s robustness. Through this process, we discovered several important insights. For example, some users did not immediately notice the sources tabs, prompting us to make these more prominent in the interface. We also identified limitations within the chatbot, such as links in the content that were inaccessible due to the data wrangling process. Additionally, browser-based issues surfaced, including unexpected session sharing between users. Addressing this, we refined our server and containerization architecture to ensure a more secure and isolated experience for each user.
In addition to different rounds of UAT, we are conducting an ongoing assessment of the impact of the chatbot as it has been launched in the department. This was planned with a workshop where we reviewed the Theory of Change for the product and identified the key impact questions to answer, which includes “User Experience: Is the experience of writing IAs improved by using the chatbot?” and “Efficiency: Does the chatbot improve people’s use of time?”. These questions guided the creation of baseline and follow-up surveys which will provide evidence for impact, alongside case-studies with teams who used the chatbot whilst writing impact assessments. Alongside all of this, the chatbot contains ways to provide both message-by-message feedback and a general feedback form that we monitor for insight into how the bot is working for its users.
We’ve already heard how the tool has helped users to research impact assessments, including both finding interesting approaches and investigating a dearth of previous similar approaches – moreover, the chatbot is improving the experience of research and drafting impact assessments, and similar work is now ongoing for other kinds of document drafting. Continuous evaluation, alongside dev maintenance, is key to continuing success.